Artificial enzymes have attracted tremendous interest in recent years and several approaches to mimic biological catalysts have been proposed. One approach is to create minimalistic catalysts based on peptides and their assemblies. Peptides are increasingly investigated in biomedical applications due to their inherent biocompatibility, biodegradability, low toxicity of metabolites and because they are building blocks of life. Short peptides can self-assemble into nanostructures, which often results in new emerging functions, not observable with their constituting monomers. One such function is catalytic activity. Little is known about the principles that govern the catalytic activity of short peptides at the sequence level. From previous studies it is evident that the residues that make up the sequence and the order in which they appear are important.
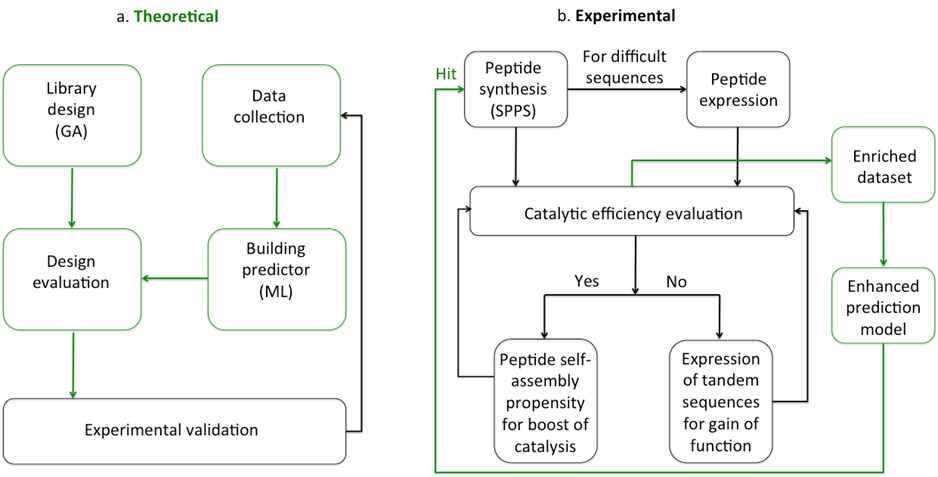
In this project, we want to combine machine learning with experimental validation to develop a more efficient and economical approach compared to the unguided experimental evaluation. We aim to discover patterns in existing data and accelerate the discovery of new catalytic peptides within a relatively small number of experiments. The overall objective is to determine whether we could use machine learning to efficiently predict the catalytic activity of short peptides and understand what are the key features that govern this process. We aim to reveal how are peptide sequences responsible for catalysis with the scope of evolving them to more complex systems, through self-assembly or tandem peptide repeats, to reach function.
In our approach we aim to encompass the entire spectrum from fundamental understanding of peptide sequences and their ability to catalyse reactions to eventual societal benefit of discovering minimalistic versions of enzymes able to be used in everyday life. The successful outcome of this project will result in a strategy able to explore broad sequence and structural spaces for future discoveries.